Scraping Speed and Parallelization
Out of the three, Scrapy is the clear winner when it comes to speed.
This is because it supports parallelization by default.
On Selenium, it’s impossible to achieve parallelization without launching multiple internet tool instances.

Memory Usage
Selenium is a online window automation API, which has found its applications inthe web scraping field.
This makes Selenium a resource-intensive tool when compared with Beautiful Soup and Scrapy.
It ships with nothing else.
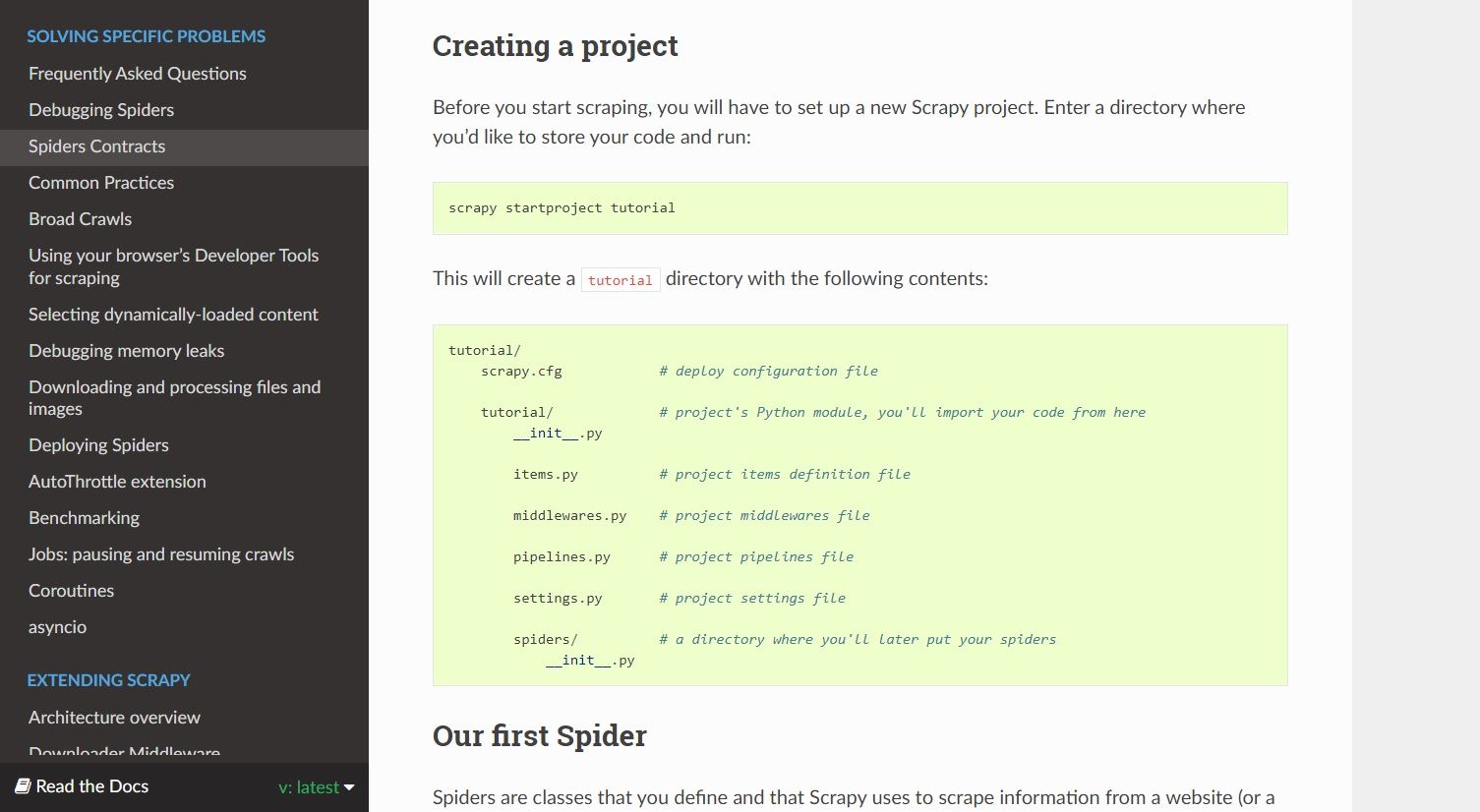
Scrapy, on the other hand, comes with the whole shebang.
you could add other functionalities to Scrapy using extensions and middleware, but that would come later.
With Selenium, you download a web driver for the internet tool you want to automate.
To implement other features like data storage and proxy support, you’d need third-party modules.
Documentation Quality
Overall, each of the project’s documentation is well-structured and describes every method using examples.
But the effectiveness of a project’s documentation heavily depends on the reader as well.
Beautiful Soup’s documentation is much better for beginners who are starting with web scraping.
Selenium and Scrapy have detailed documentation, no doubt, but the technical jargon can catch many newcomers off-guard.
Support for Extensions and Middleware
Scrapy is the most extensible web scraping Python framework, period.
Beautiful Soup can select HTML elements using either XPath or CSS selectors.
It doesn’t offer functionality to scrape JavaScript-rendered elements on a web page, though.
Web Scraping Made Easy With Python
The internet is full of raw data.
Web scraping helps convert this data into meaningful information that can be put to good use.
Whatever framework or library you go with, it’s easy to start learning web scraping with Python.
